
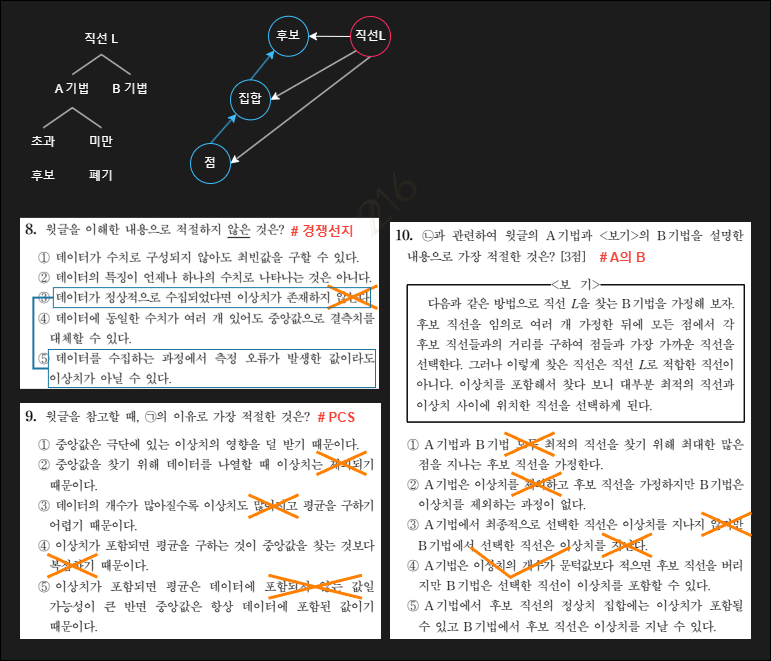
Representation
기술 지문 중 쉬운 편에 속한다. 그 이유는 대부분의 기술 지문이 cause of 관계에 복잡성을 반영하고 있지만 이 제시문은 독특하게 양상 측면을 강조하고 있기 때문이다. 물론 제시문 자체는 다양한 개념 간 관계를 포함하지만 정작 문제 풀이 측면에서 강조되는 부분은 단정과 개연 범주였다. 특히 독해 과정에서 '-도'에 주목할 가치가 있다. 이는 요건의 맥락과 달리 개연적인 서술을 나타낸다. 이러한 양상은 8번 문항에 반영되었다.
문제 해결 과정을 인과 관계를 이용하여 나타낼 수 있는데 이를 'PCS 도식'이라 한다. 이는 연쇄 인과 과정의 한 유형이고, 해결방안은 언제나 원인과 억제 관계에 놓인다.
- PCS: 문제(Problem), 원인(Cause), 해결방안(Solution)으로 구성되어 연쇄 인과를 이룬다.
결측치와 이상치는 데이터의 일부, 즉 구성요소이다. 이 두 항은 데이터 왜곡을 일으킬 수 있다. 제시문에 언급되지 않았어도 이것이 맥락 상 좋지 않은 상황이라면 원인을 억제시키는 변항이 해결방안이 될 것을 예측할 수 있다. 결측치에 따른 왜곡을 해결하는 방안 중 하나는 대체이다. 이는 대체가 유일한 방법이 아니라는 것을 함축한다. 출제자가 제시문 길이를 짧게 구성한 만큼 문제의 난이도에 잠금 장치를 건 것으로 보인다.
대체값의 속성에는 평균, 중앙값, 최빈값이 있다. 평균의 정의와 구하는 방법은 지문에 제시되지 않았는데, 이것이 고1 공통 교육 과정이기 때문이다. 9-④에서 볼 수 있듯이 평균을 구하는 것에 대한 복잡성은 제시문에서 그 근거를 찾아볼 수 없다.
평균은 크기를 고려하고, 중앙값은 데이터를 크기 순으로 나열한 뒤 위치만을 고려한다. 크기 그 자체에 대한 평균과 크기 순에 따른 중앙값은 방식 측면에서 서로 다른 과정으로 보아야 한다. 순위에 관한 것은 중앙값을 이용하며, 이에 대한 예시는 다음 문단에 등장한다. 따라서 ㉠이 뒤따라 나오는 것은 놀라운 일이 아니며, ㉠의 이유는 중앙값이 이상치에 의한 왜곡에 덜 민감하기 때문이다. 양적 서술에 주목하자.
이상치는 오류에 의해 생길 수 있지만 정상적인 경우, 다시 말해 오류가 아닌 경우에도 발생할 수 있다. 따라서 측정 오류가 이상치의 필요조건이 아니거니와 충분조건에 해당하지도 않는다. 출제자는 이에 근거하여 경쟁선지를 8번 문항에 삽입했다. 오류의 여부와 무관하게 데이터 수집 과정에서는 이상치가 생길 수 있는 것이다. ③과 ⑤는 서로 경쟁한다. 출제 구성 측면에서 어느 선지든 간에 맞는 말로 고치려면 개연적인 서술로 바꿔주면 된다.
데이터의 형태는 수치 뿐만 아니라 직선으로도 나타날 수 있다. 출제자는 '좌표평면' 개념을 이용하여 이를 모델링했다. 점들로 구성된 직선을 통해 데이터의 특징을 나타내는 것을 이용하여 8-②를 구성했다. ㉡은 이상치를 포함하는 상황으로 논의영역을 한정한다. 직선 L을 찾기 위해서는 지문 속 기법 또는 <보기>의 B 기법이 쓰일 수 있다. 그런데 문제 풀이 측면에서 중요한 것은 '무작위' 개념이다. 이 어휘는 수학에서 '임의의'로 대체 가능하며, 모든 것에 대한 것과는 구별된다. 예컨대 A 기법에서 두 점을 무작위로 고른다면 이 두 점은 이상치가 포함될 수 있지만 그렇지 않을 수도 있다. 즉 '무작위 논의영역'에서 특정한 원인은 존재하지 않는다. 그러므로 이로부터 특정한 결과가 보장되지 않는다.
마지막 문단은 부분 관계를 이용하여 모델링하면 좋다. 점들이 모여 정상치 집합을 이루고 문턱값 조건에 부합하는 후보 직선은 최종 후보군이 될 수 이다. 이 후보군 가운데 정상치 집합을 이루는 점들의 개수가 최대인 직선이 직선 L로 설정된다. 즉, 직선 L을 결정하기 위해서는 문턱값 조건과 점 개수 최대 조건을 모두 만족해야 한다. 개념적으로 설명하자면 모든 필요조건이 모여 충분조건이 되는 것과 같다.
Filtering
- 8번 문항
- ③: 경쟁 선지에 대한 가시성이 매우 뚜렷하여 털어내기 쉽다.
- 9번 문항
- ①: 설정된 논의영역은 값을 구하는 방법이 아닌 그 값이 왜곡을 보정할 수 있다는 내용을 포함한다. 즉, 이상치가 제외된 상황, 데이터와 이상치의 상관관계, 평균/중앙값과 데이터 간 포함관계는 ㉠의 이유로부터 논점을 이탈한다.
- 10번 문항: <보기>에서도 지문과 마찬가지로 '무작위' 표현이 쓰였다. ④를 관찰하는 과정에서 A의 B 함정에 유의하자. 이상치는 점을 이루는 구성요소이다. 문턱값 조건이란 점의 개수에 관한 것이지 이상치에 국한되는 개념이 아니다.
- ⑤: 개연적 진술에 주목하자. '무작위'의 의미는 바로 이러한 것을 말한다. A 기법에서 두 점을 무작위로 선택하면 후보 직선이 된다. 이에 이상치가 포함될 수 있고 그렇지 않을 수도 있다. B 기법도 마찬가지로 후보 직선을 임의로 선택할 수 있으므로 어떤 직선은 이상치를 지날 수 있다.
